👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’ve been forwarded this email, you can subscribe here. What is Reliability Engineering?A history of SRE practice and where it stands today, plus advice on working with reliability engineers, as a software engineer. A guest post by SRE expert and former Googler, Dave O’ConnorFor software engineers, the job involves more than just building software systems; these systems must also be reliable. This is easy enough for a website with a small number of visitors; but the larger the system gets, the trickier reliability is to achieve. There’s a huge amount of complexity involved in making an app or website with tens, or hundreds, of millions of daily users work reliably for (almost) all of them. Google pioneered the concept of Site Reliability Engineering (SRE), and it has become a pretty mainstream discipline with many mid size-and-above tech companies having dedicated SRE or reliability teams. To find out more about SRE and reliability engineering in general, I reached out to SRE veteran, Dave O’Connor. He was at Google in 2004 – working with the team, from where the SRE discipline emerged just a year before, in 2003. Today, Dave covers:
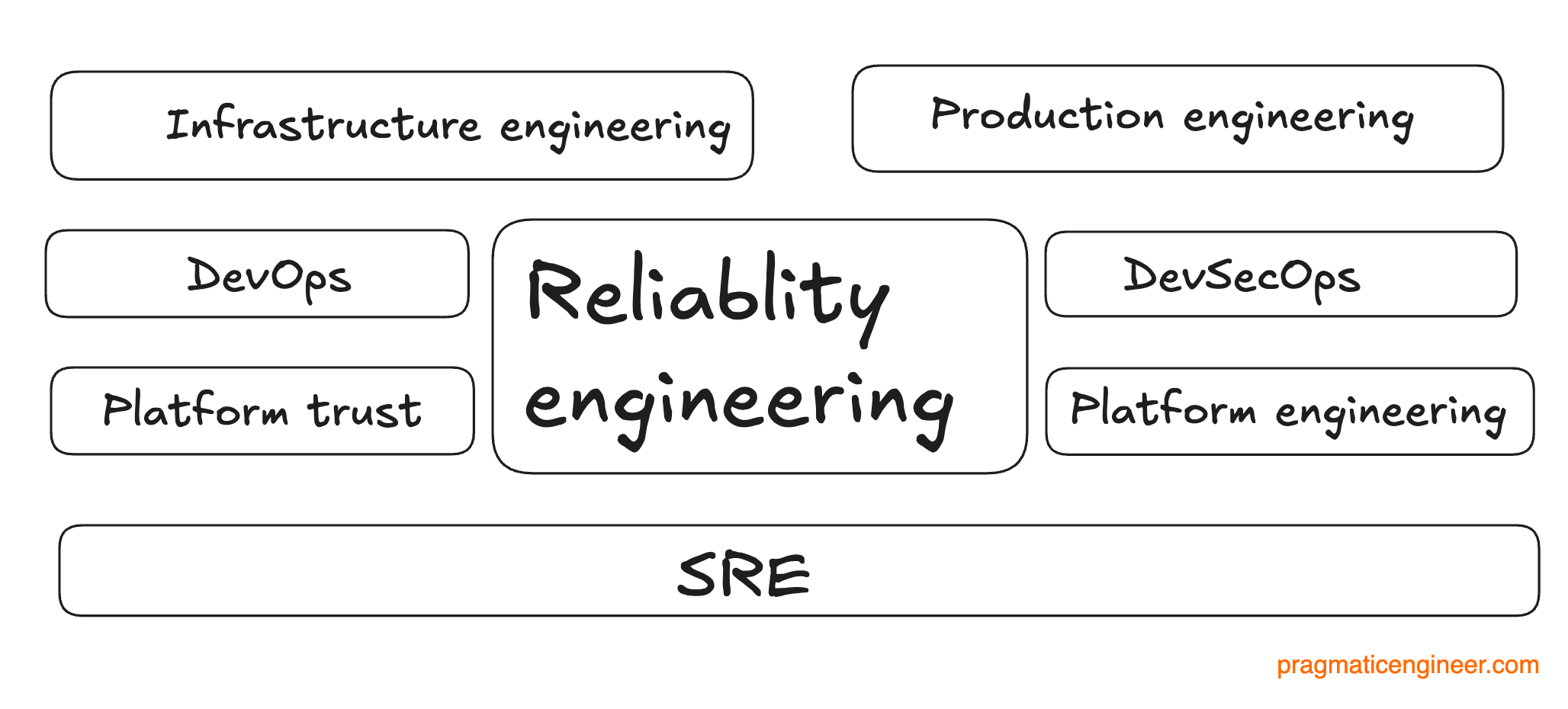
The bottom of this article could be cut off in some email clients. Read the full article uninterrupted, online. With this, it’s over to Dave. Hi, I’m Dave. I’ve been a site reliability engineer (SRE) for 20 years, before many folks outside the Google ecosystem called it that. I joined the company in 2004, on a team tasked with (re)installing and (re)configuring machines in the fleet. We quickly realized that due to sheer numbers, it was not a job that could be done by humans at the then-current scale, let alone at the scale expected. At the time, the common capability to run and manage more than a few hundred machines simply didn’t exist. Then began the chartering of what became known as ‘site reliability engineering’ at Google. The rest, as they say, is history. Several years later, that history started to be told in Site Reliability Engineering (I contributed chapter 29), and various publications thereafter. Since leaving Google in 2021 after 17 years as an SRE, I’ve led SRE and production groups at Elastic and Twilio, and I’m currently freelancing as a leadership practitioner for busy teams (SREs included), and as a coach for engineering leaders, focusing on reliability engineers. Check out my consulting services, and coaching practice. 1. Common termsI use the term ‘reliability engineering’ in this article. This is because as a set of practices, it stands on its own and can be implemented via specialized ‘SREs’, the ‘DevOps’ model, or individually as software is built. Many publications go to great lengths to make this distinction, and the question of whether reliability should be done by specialized SREs, or everyone, is a resounding ‘it depends’. See my article 6 Reasons You Don’t Need an SRE Team for why I believe many companies don’t need a dedicated function. As with any engineering specialization, anybody can do reliability engineering up to a point. The decision on hiring or building a dedicated SRE group is similar to the choice of whether to hire a dedicated QA, or an information security group. Does the business care enough about the outcomes to dedicate people and organizational headspace to it? Often, the answer is initially “no”. However, almost every enterprise encounters novel and domain-specific engineering challenges at some point, and in these situations dedicated SREs provide better outcomes, tailored to individual needs. “Site reliability” as a name was coined by Google. The “site” in question was google.com. However, the role has grown since; for many years at Google I led the SRE group in charge of all the storage and databases. These were not ‘sites’ per se, but the name had stuck by that point. As with most nascent engineering functions, folks who do reliability engineering go by many titles:
These titles all encompass pretty common practices. It’s also argued – correctly, if you ask me – that reliability engineering predates what Google did. Many of its common-sense or even specialized practices are taken from other disciplines. For example, the concept of the incident commander role for large-scale outages derives from the US Federal Emergency Management Agency (FEMA), founded in 1979. 2. HistoryAs computing has evolved and gone increasingly online, our needs have scaled beyond the capability of humans to perform tasks, or even understand the scale at which we find ourselves doing things. When there are 100,000+ machines, it’s impossible to eyeball a graph of all data points like servers or machines. We can not take a well-understood administrative action on a machine if we have to replicate it 100,000 times. In the early 2000s, many enterprises went from a manageable number of physical computers to large numbers of servers. These servers performed one function and were clustered, or they could take more generic workloads. As Gavin McCance, Compute Services lead at CERN, put it, we started thinking of individual machines as cattle, not pets:
In the early days, the frame of reference for how many “a lot” of machines was, shifted almost monthly. At Google in around 2006, I went on a site visit to another large tech employer in Ireland, during which our group peered through a small window into “the largest datacenter in Ireland”, numbering thousands of machines. Cue some raised eyebrows and polite ‘ahems’ because we knew we had a room with twice as many machines, located half an hour’s drive away. Google’s scaling ability lay in being able to assemble and power machines, but also in being able to pour concrete and purchase supporting equipment like generators, when supply chains simply weren’t set up for our scale. It represented an enormous uptick in the amount of real, difficult, and unsolved engineering problems in delivering services. For 99% of enterprises, this kind of massive scaling up in servers isn’t (nor should be) a core competency. Hence the explosion in cloud computing because amassing the human expertise to understand and run all layers in the stack is far beyond the purview of most businesses. The early SRE roleAt places like Google, it made sense to build the expertise and technology to cover all layers of the stack, from the frontend serving infrastructure and network links, back to the physical machines and power infrastructure on the ground. This was for reasons that can be linked back to one thing: scale. When I joined the tech giant the number of physical machines was in the process of sailing comfortably into six digits, crossing 100,000 and growing fast. By comparison, at most enterprises, a couple of hundred machines was considered a pretty large footprint. This had two major forcing functions, both related to scale:
An additional forcing function for us was Google’s leadership’s almost fanatical desire for reliability and speed. Larry, in particular, cared a lot. Just as Gmail was launching and offering users an previously-unthinkable entire gigabyte of email storage, we were aiming for levels of precision and speed in serving content that were unheard of in most industries. The fervent belief of Google’s founders was that speed and reliability mattered more than features. This belief was coupled with the understanding that we couldn’t achieve it traditionally, which made it an existential issue. The level of investment in building out all layers of the serving stack was a case of “because we can”, but also “because we have to, as nowhere else does what we need”. There was never a question of whether traditional ‘ops’ would work at Google. We needed a specialized role, staffed by folks familiar with the problem space and engineering methods required to make it work. In 2003, the SRE role was born. Ben Treynor Sloss had been tasked with building Google’s “production team” and in his own words, he built “what happens when you ask a software engineer to design an operations team.” This turned into the birth of the SRE function at Google. From the outset, SRE was staffed in varying measures by systems/operations experts and software engineers. A large part of the remit of the team was to build the tools and practices required to operate Google’s fleet. I joined as one of the first non-US SREs, based in Ireland. My background is in systems administration, and my previous employer’s machine fleet numbered somewhere in the high double-digits. I was one of the newer, specialized breed of “sysadmins who code”. We didn’t have a snappy name, but did have the drive to embody the three virtues of ‘laziness, impatience and hubris.’ When I joined, my first gig was ‘babysitting’ Gmail’s machine fleet. Basically, the job was to ensure there were enough machines to serve storage and serving needs, and to juggle decisions on waiting for tools and processes to catch up, or building them. In particular, many practices for working in distributed teams containing up to nine time zones, came from the early experience of collaborating with our SRE and product development counterparts in Mountain View and other offices. Industry ConvergenceEventually, other companies caught onto the scaling issues, especially the hyperscalers. Each had their own approach, but over time, the notion grew industry-wide that making things reliable was a real-life engineering discipline, not simply ‘ops’. This step saw a number of terms coined to describe this engineering, including ‘DevOps’. At its core, this was the notion that the disciplines and practices of reliability engineering should be ingrained into the overall engineering organization. At places other than Google, this mostly took the form of combined developer/operations roles (i.e. “you build it, you run it”), which differed from Google’s implementation, but the practices were similar. Around this time, Google started opening up about SRE, eventually publishing the first SRE book, and follow ups. Conferences such as USENIX SRECon, Devops Days, and other movements have solidified reliability engineering as a discipline that scales well beyond Google. Indeed, the company has become a consumer of many state-of-the-art developments. 3. Reliability Engineering TodayReliability engineering is still in its growth and adoption phase. Unreliable software and systems which are slow or function incorrectly, are no longer tolerated by businesses and direct consumers. Fast, reliable internet access is becoming ubiquitous, and the services people use must be the same. But aiming for near-perfect reliability scales costs exponentially. It’s estimated, based on experiences at AWS, that every “nine” of additional guaranteed availability (the difference between 99%, 99.9% and 99.99% uptime) scales overall costs by roughly ten times. This includes staffing, development and testing costs, and may only partially account for the opportunity costs of a necessarily slower release cycle. But slower release cycles aren’t for everyone! If you’re in a product space which can’t tolerate spending too much time and energy on testing and resiliency, the right answer may well be to aim lower. It’s sensible practice for any organization to explicitly state how much they care about reliability. Know that it is not a race to the top: be realistic about balancing the price you’re willing to pay, with the reliability the business needs! In the end, business outcomes win. I have been in several versions of the same meeting where a product owner demands a certain number of ‘nines’ of availability, but when probed on what the business outcome of falling below this target is, they don’t really have an answer. This especially applies to non-serving systems and data pipelines, which can be behind in processing by several hours with no ill effects. However, it’s often seen as easy or necessary to demand to-the-minute SLAs from the outset, without reference to the ‘North Star’ of business needs. As in disciplines such as security, there is a tradeoff. The downside when things go wrong is bad, but we don’t have carte blanche to do absolutely everything for extra reliability. It may be possible to neglect these areas entirely and risk the enormous downside of a security incident or outage, or to pursue reliability goals at the expense of the core mission. Try to avoid implementing what Google does for its SRE practice. One of the authors of the original SRE Book, Niall Murphy, famously tore up a copy of it during a keynote at SRECon in 2022. But far from disavowing the book’s content, he was sounding a note of caution about copying what Google does, wholesale. Absorbing Google’s approach effectively is not about copying as much of it as possible, it’s about discovering which elements make sense for you and what you’re building. Since departing Google, I’ve worked with more than one company with its own “SRE Book Club”. This is great because there’s a lot of knowledge contained therein. However, I never saw rooms full of database admins poring page-by-page over database design publications and figuring out which features to include wholesale in their own setup, and this definitely applies to a modern SRE practice. The Google model of building everything yourself is just one way. It worked in the 2000s, but likely wouldn’t work today. The availability of technology and products that didn’t exist when Google was building SRE makes the tradeoffs a lot more understandable and explicit, in hindsight. I go into more detail on this topic in my article, “A Short History”. 4. Four promisesAt its core, reliability engineering is this:... Subscribe to The Pragmatic Engineer to unlock the rest.Become a paying subscriber of The Pragmatic Engineer to get access to this post and other subscriber-only content. A subscription gets you:
|
What is Reliability Engineering?


Subscribe to:
Post Comments (Atom)
When Bad People Make Good Art
I offer six guidelines on cancel culture ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏...
No comments:
Post a Comment