👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’ve been forwarded this email, you can subscribe here. How to debug large, distributed systems: AntithesisA brief history of debugging, why debugging large systems is different, and how the “multiverse debugger” built by Antithesis attempts to take on this challenging problem spaceDebugging is one of those things all engineers do, but little has changed in how we debug for decades. For example, debugging by printing to the console output or by logging is still pretty common, even though there’s decent debuggers that can be used across IDEs. Believe it or not, some debugging tools today are actually less advanced than in the old days. Steve Yegge, head of engineering at Sourcegraph – said last year:
This stagnant rate of progress makes it very interesting that there’s a small engineering team working today on building a much better debugging tool, which specifically focuses on debugging large and distributed systems. It’s called Antithesis, and is the focus of this article. Today, we cover:
As always with these deep dives about a vendor, this publication has no affiliation with Antithesis, and was not paid for this article. Check out our ethics policy. The bottom of this article could be cut off in some email clients. Read the full article uninterrupted, online. 1. Brief history of debuggingDebugging and software development have gone hand in hand since the earliest days of computing. But why do we call it ‘debugging’? The etymology is a bit obscure, but it could include a real-life insect. First “debugged” computerIn 1947, a team of scientists at Harvard University including computer science pioneer, Grace Hopper, found a moth trapped in a relay of the Mark II mainframe computer which was causing it to malfunction. The fault was documented, and the moth itself was added to a hand-written record, reading: “...first actual case of bug being found.”
Faults were called “bugs” before this incident, but the serendipitous episode may have helped cement the term “debugging” in the lexicon. Several computer science papers from the 1950s mention “debugging” in passing, which suggests the word was in use and its meaning was common knowledge among professionals. It also appears in the 1963 manual of the first time-sharing operating system, the Compatible Time-Sharing System (CTSS.) Evolution of debugging toolsProgrammers have always built tools to make their lives easier, and debuggers are a case in point. Here’s how the toolset evolved from the 1960s. 1960s: punch card era. The earliest debugging tools:
1970s: (symbolic) debuggers. New, powerful programming languages like C, FORTRAN and COBOL were developed in the ‘70s, which allowed fetching of symbol maps that showed the memory addresses of variables. Symbol maps were used for more efficient debugging, as they made it unnecessary to manually track memory addresses. The tools in use today are symbolic debuggers. Late 1970s: breakpoints. With the ability to inspect the memory of a running program and to get a memory dump, the next debugging task is to halt program execution on a given condition, like a variable reaching a certain value. Breakpoints allow for precisely that. The core functionality of halting program execution emerged in the 1940s, with involved approaches like removing cables, deliberately causing program crashes, and via hardware switches. Over time, the utility and usability of breakpoints evolved, and by the end of the ‘70s, they were in symbolic debuggers in ways recognisable today. More advanced tools added the option of allowing a program to advance one step forward (step forward) and the more complex functionality of going back (step back.) Mid-1980s: “modern debugging.” From the 1980s, the software development experience continued to evolve with better terminals, more interactivity, and ever-tighter feedback loops. Debugging improvements followed a similar pattern. For example, in 1983 Turbo Pascal introduced its IDE with built-in debugging capabilities – which might have been the first “mainstream” IDE with debugging enabled. Graphic debugging tools with visual breakpoints and output were innovations of this time. Remote debugging – debugging programs running over networks – became possible with the spread of the internet. Today’s modern debugging tools have modern features, such as:
2. Antithesis’s ‘multiverse debugger’Antithesis was founded in 2018 with the vision of a better way to test systems, and it has raised an impressive $47M (!!) in seed funding. The business model is usage-based pricing, based on the number of CPUs used for testing activities; a good analogy is Amazon renting out its EC2 servers. Today, Antithesis sells cores on an annually-reserved basis, with a minimum for getting started with, and hopes to offer more flexibility in the future, I’m told. Time-travel debugging tools are usually limited to functional languages where state management is simple, or to deterministic environments; like in well-defined sandboxes. For most real-world programs, no time travel option is available for debugging, so when a backend service crashes non-deterministically, there’s no good way to turn back time and investigate it; the best option is usually to add more logging to help explain future crashes. Building a time machineThe Antithesis team spent several years building a system that acts like a time machine. It wraps your current system, and lets you rewind your steps. Within the “wrapper”, to rewind the state of the system to 5 seconds earlier, you type: branch = branch.end.rewind(5).branch Files deleted within the last five seconds come back, including if deleted permanently without being put in deleted file storage. Any changes made in files since are also undone. Creating the time machine means creating a deterministic simulation, which can progress from its starting point to the future, arbitrarily. It can go back in time, too, which raises interesting possibilities. For example, if your server crashed: wouldn’t it be great to “rewind” time and attach a debugger? In a simulated system, you can do this: simulate the system to the point where the process will crash, then add a debugger or export a memory dump. Similarly, if a user reports that their session was slow: it’s now possible to go “back in time” by recreating their session, and attaching a debugger. Having a deterministic simulator creates previously hard-to-achieve scenarios, such as:
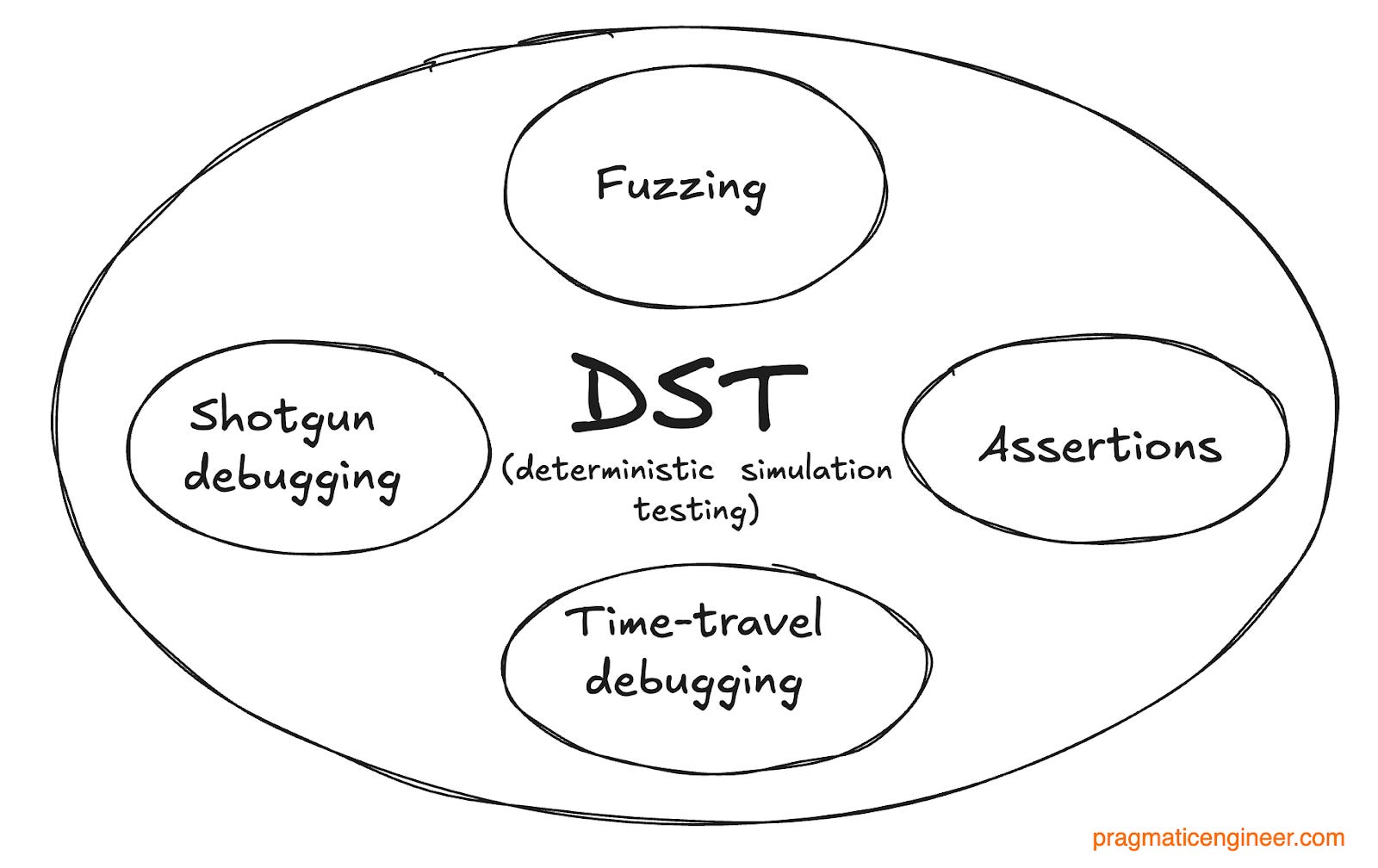
What Antithesis doesAntithesis is not only a time-traveling debugger, though. A good way to describe it is as “Deterministic Simulation Testing (DST) as a service.” Deterministic Simulation Testing (DST) is a technique of building a simulation in which software can run in a single thread, and where you’re in control of all variables like time, randomness, etc., in order to achieve determinism during testing.
DST is a combination of:
Doing Deterministic Simulation Testing is really hard for any system because you have to build everything from scratch. No existing frameworks and libraries without support for all time-traveling, debugging, fuzzing, etc, can be used. One of the first “proper” usages of DST was within the distributed database, FoundationDB, one of whose creators is Antithesis cofounder, Will Wilson. Because implementing DST is so difficult, Antithesis made the computer/hypervisor deterministic, instead. This means anything that runs on this Antithesis computer/hypervisor can be tested with DST, without doing everything yourself. And thanks to running a fully deterministic environment, Antithesis can manipulate it into weird states on purpose, which allows developers to inspect weird states and bugs to find out their causes. Read more on how Antithesis works. 3. Q&A with Antithesis co-founder, Will WilsonThe company’s CEO took some questions from us, and in this section the questions are italicized, with Will’s responses in normal text. How debugging large systems is differentThe Antithesis tool was built to debug large and complex systems, but how are these systems different from common ones like single services, apps, and single-threaded websites? ‘A few things make large systems different:
‘All of the above make testing and debugging large systems much harder, especially the first three points. Many failure modes of large-scale systems are “external” or environmental, and to do with hardware faults, network messages getting delayed, or weird pauses on a thread. These are harder to reason about in advance, and they’re monumentally harder to test for and debug, as they may depend on highly specific conditions or timings that are almost impossible to reproduce on demand. ‘The paradox of distributed systems is that a one-in-a-million bug can be a huge urgent problem because you’re processing millions of requests all the time, so the bug will occur frequently. But, it’s still a one-in-a-million bug, so a test probably won’t reproduce it!’ How Antithesis is usedWhere does Antithesis fit into customers’ software delivery and process timelines? ‘We see customers using Antithesis in very different ways. There are teams who run short tests on almost every PR, or who run long tests overnight or weekends, and some teams only pull it out when trying to track down a really crazy bug. ‘We don’t tell our customers they should eliminate any of their existing tests because it’s probably inexpensive to keep them, and we don’t want to be the cause of any outage or emergency. That said, many customers stop investing as much in non-Antithesis tests, and instead try to find ways to use our platform for as much testing as possible. ‘Some customers have come up with really creative ways to use our platform. For example, who said this tool can only be used for hunting bugs? It’s a general platform for looking for any behavior in software systems. For example it can help answer questions like:
‘Most of what Antithesis “replaces” is human effort of the really annoying, unpleasant kind, like adding logging, then waiting for it to happen again in production. Or designing weird, ad-hoc fault injection systems in end-to-end tests. Or writing a script to run an integration test dozens of times to chase down an intermittent problem that only occurs once every ten runs. Basically, the stuff no programmer enjoys doing.’ 4. Tech stackWhat is the tech stack behind Antithesis? DST is hard to do with existing libraries, so which frameworks you might use instead of writing a bespoke one? ‘We have a pretty bad case of “not-invented here” syndrome. Basically, compared to most companies, we see a larger cost to adopting lots of third-party dependencies. So we bias towards building tools in house that do exactly what we need, which means our tech stack is very “home-grown”. ‘Languages we use often:
‘Our major dependencies:
‘Our homegrown stack is surprisingly large!
‘Our homegrown stack is huge! One of the coolest things about working at Antithesis as an engineer is that if there’s any computer science topic you’re interested in, there’s a good chance we do it, at least a little. Building a database‘We started using BigQuery very early because the pricing model is unbeatable for a tiny startup with bursty workloads. But the data model did not make much sense for us. ‘Our use case is to analyze ordered streams of events: logs, code coverage events, etc. But because we have a deterministic multiverse which can fork, the stream of events form a tree structure rather than a single linear history! But BigQuery is not well set up to handle trees of events, and neither is any other SQL database. ‘We managed to putter along for a while with crazy hacks. For instance, we built a new data structure called a "skip tree", inspired by the skip list which we implemented in SQL. This data type greatly improved the asymptotic performance of our queries (the performance characteristics at scale). However, we eventually got to the point of regularly crashing BigQuery's planner; at which point we knew we had to move to something else. ‘We evaluated Snowflake, and its Recursive CTE feature, and also evaluated a large number of other SQL and NoSQL databases, but nothing fundamentally fixed the problem. ‘We were hesitant to build our own database for ages, until a company hackathon where a team tried writing a proof-of-concept analytic database for folding Javascript functions up and down petabyte-scale trees, thrown together in a week using Amazon S3 and Lambda. It actually worked! ‘We're cautious, and a lot of people on our team have built databases before. We know that the hardest part of building a database is not getting started, but towards the end of the project with testing and operationalizing. But we do have this really great technology for testing distributed systems! ‘We decided to write a custom database for our needs, 100% tested with Antithesis. We would have no other test plan except for running it with Antithesis! We are now nearing the end of the project, and so far, it’s going well! ‘If we succeed, it would solve a huge number of production issues with BigQuery, and enable us to launch some amazing new features. Plus, this project gives us the ultimate empathy with customers. 5. Engineering team and cultureTell us about the engineering team’s values and practices... Subscribe to The Pragmatic Engineer to unlock the rest.Become a paying subscriber of The Pragmatic Engineer to get access to this post and other subscriber-only content. A subscription gets you:
|
How to debug large, distributed systems: Antithesis


Subscribe to:
Post Comments (Atom)
Top 3 UX Design Articles of 2024 to Remember
Based on most subscriptions ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ...
No comments:
Post a Comment