👋 Hi, this is Gergely with the monthly, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’re not a full subscriber, you missed the issue on AI tooling reality check for software engineers, AWS shifting its focus away from infra, the Trimodal nature of tech compensation revisited, and more. Many subscribers expense this newsletter to their learning and development budget. If you have such a budget, here’s an email you could send to your manager. The biggest-ever global outage: lessons for software engineersCybersecurity vendor CrowdStrike shipped a routine rule definition change to all customers, and chaos followed as 8.5M machines crashed, worldwide. There are plenty of learnings for developers.Unless you were under a rock since last week, you likely heard about the CrowdStrike / Windows outage that took down critical services like airlines, banks, supermarkets, police departments, hospitals, TV channels, and more, around the world. Businesses saw their Windows machines crash with the “Blue Screen of Death,” and no obvious fixes – at least not initially. The incident was unusual in size and scale, and also because it involved software running at the kernel-level; a factor which gives this us all the more reason to take a look at it. Today, we cover:
Note: this is the last issue before The Pragmatic Engineer goes on summer break. There will be no The Pulse on Thursday, and no new issues next week. We return on Tuesday, 6 August. Thanks for your continuing support of this publication! 1. RecapLast Friday (19 July,) the largest-ever software-initiated global outage hit machines worldwide. Millions of Windows 10 and 11 operating systems used by societally-critical businesses like airlines, banks, supermarkets, police departments, hospitals, TV channels, etc, suddenly crashed with the dreaded “Blue Screen of Death,” and no obvious way to fix them. This was a truly global outage; the US, Europe, Asia, and Australia, were all hit. Global air travel descended into chaos, and in Alaska the emergency services number stopped working. In the UK, Sky News TV was unable to broadcast, and McDonalds had to close some of its Japanese outlets due to cash registers going down. In total, tens of thousands of businesses and millions of people were impacted. Meanwhile, in the world of Formula One racing, the Mercedes team saw its computers crash at the Hungarian grand prix. Ironically, one of the team’s sponsors is… CrowdStrike. Some photos of the outage in the wild:
All the business victims of this mega crash were customers of cybersecurity company CrowdStrike, which is the market leader in “endpoint security,” with around 20% market share. It installs software on Windows / Linux / Mac machines, and runs antivirus, firewalls, intrusion detection and prevention systems (IDP,) among others. What unleashed the global carnage was a single update by Crowdstrike to its ‘Falcon’ product. We know 8.5M Windows machines were impacted globally from Microsoft sharing this number, later confirmed by CrowdStrike. Worst-hit of all might be Delta airlines, where around a third of flights (5,000) were canceled in three days. Even on day 4, Delta had to cancel another 1,000 flights as it recovered, and is on the hook for cash refunds for impacted customers. 2. Root causeA few hours after Windows machines running CrowdStrike’s software started crashed, the company issued an update:
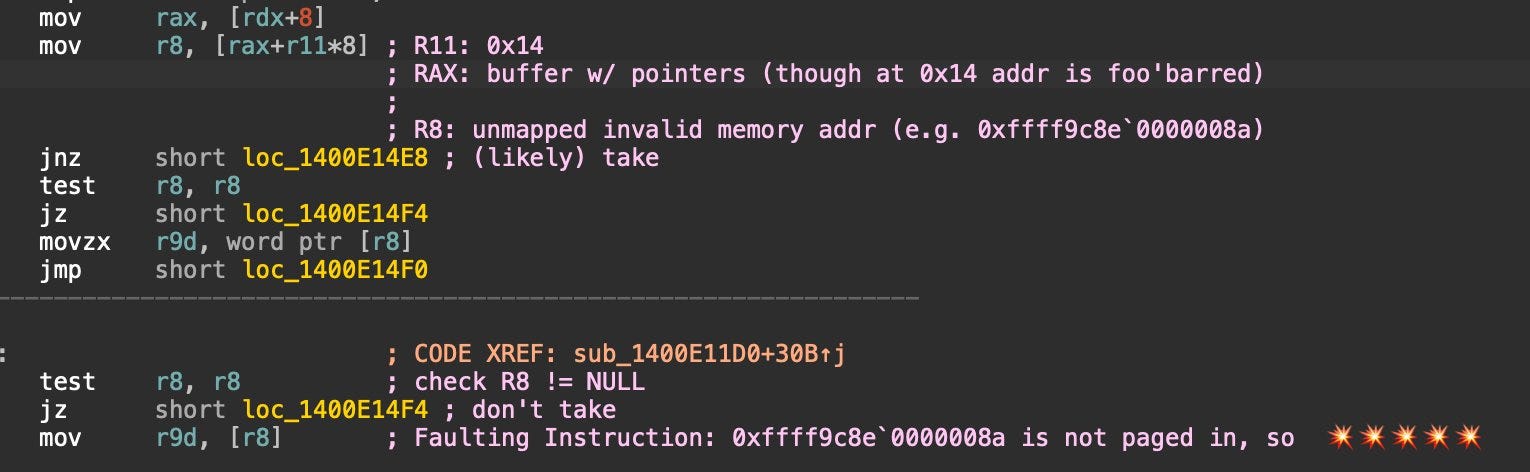
What happened is the company pushed out a “content” file (a binary file) to all customers at once, which then crashed the operating system. But how did it happen? As the incident was ongoing, some devs attempted to reconstruct what happened. Here are details from Patrick Wardle: 1. The process that crashed Windows is called “CSAgent.sys” 2. The instruction that crashed is the Assembly instruction “mov r9d, [r8].” This instructs to move the bytes in the r9d address to the r8 one. The problem is that r8 is an unmapped address (invalid), and so the process crashes!
3. The crash was caused by the CSAgent.sys process reading a new “content” file CrowdStrike pushed to all clients called “C-00000291-*.sys” (where * can have additional characters.) Something went wrong related to this file and the parsing of it. A day later, CrowdStrike shared more details: 1. The goal of the update was to detect maliciously-named pipes. CrowdStrike’s Falcon product observes how processes communicate on a machine, or across the network, to try and pinpoint malicious activity. The update was adding a new rule file to filter for suspiciously named pipes. A named pipe in the Windows world is a “named, one-way or duplex pipe for communication between the pipe server and one or more pipe clients.” These pipes can be used for inter-process communication (two processes talking to each other; here’s an example of processes sensing files between one another, or to communicate over the network. Named pipes are a common concept with operating systems for interprocess communication: Unix also uses this concept. 2. Released a new configuration file with new rules/naming. CrowdStrike calls config files that define behavior rules, like names for suspicious names pipes, “Channel files.” They store all these channel files in the location C:\Windows\System32\drivers\CrowdStrike\. These are numbered files, and the rules for named pipes are under number 291. Therefore, every file with the naming pattern “C-00000291-*.sys” is a rule for this category. CrowdStrike released a new naming file in the update. 3. An unhandled error crashed the process and the operating system. While I’m itching to know about what the error actually was, CrowdStrike has only shared a very brief summary:
So, somehow, parsing these new naming rules resulted in an Assembly-level instruction that tries to move a memory location to an invalid location. This is what made Windows devices crash everywhere. 3. A slow, manual fixMitigating this outage was a lot more complicated than usual because a simple revert was insufficient. IT staff had to physically access each individual machine:
CrowdStrike posted mitigation steps for IT admins and developers wanting to get themselves unblocked, a few hours after the incident. The steps were:
The recovery process might need a local administrator on a machine with the right to delete the offending file. The steps are specialized enough that regular users would struggle to perform the recovery: and so at most companies it’s up to IT staff to manually fix every machine. Plus, at many places all Windows laptops were impacted. An IT admin shared a glimpse of the task, posting an image of 120 of 2,000 laptops to be fixed in one weekend, ideally!
As software engineers, when we see a highly manual process our first thought is whether we can automate it, or do it faster in a clever way. With 8.5M machines needing resets, it’s obvious a manual process is incredibly time consuming. So independent developers, and also Microsoft, stepped in:
Four days after the outage, most of the 8.5M impacted Windows devices weren’t fixed. It turns out that crashing operating systems at scale is a lot harder to recover at scale than applications, for which patches can be sent out to clients (mobile and desktop apps,) or when the fix can be done server side (services, backend applications, web apps.) 4. Who’s responsible?It was a little amusing that the news initially reported this as a “Microsoft outage” or a “Windows outage” because it’s a bit distant from the facts. So who “owns” the world’s biggest-ever software crash? CrowdStrike – obviouslyNeedless to say, most blame lies with CrowdStrike. We can only speculate at this point about which areas were skipped, or done insufficiently thoroughly. Hopefully, we will learn more in a public-facing postmortem. Meantime, here are some questions that CrowdStrike should be asking – and, most likely, is: 1. Was the change tested, and how? Was the change in this config file (C-00000291-*.sys) tested in manual and automated scenarios? If so, how did the tests pass, and why did the crash happen in production? A more interesting question that only CrowdStrike can answer is how the configs were tested in an automated way; and indeed, were they? We know testing environments can never replicate production in full, so it’s expected that bugs can make their way through tests, undetected. 2. Were these config changes dogfooded? Was this change rolled out to CrowdStrike staff, before release to the public? If yes, did some CrowdStrike employees also see their OSs crash? If yes, then why did the rollout proceed? If there was dogfooding, but no employees’ machines crashed; an interesting question is: why not? 3. Was there a canary rollout? We cover the topic of canarying in Shipping to Production:
Canarying is a subset of staged rollouts:
Did CrowdStrike use these approaches, or was it more of a “YOLO rollout,” where the configuration file was pushed to all customers at the same time? Right now, we don’t know. From the incident response communication, it sounds like the change was more a “YOLO rollout” because the changed file was labeled as “content,” not business logic. This is despite it containing rules on how to detect named pipes, which you could argue is business logic that should be rolled out in phases, not all at once! 4. Does CrowdStrike assume that binary (“content”) files cannot break software running at kernel level? Common rollout strategies for shipping code were likely absent when shipping these new configuration files. Did CrowdStrike assume – implicitly or explicitly – that these “content” files could not crash the process? CrowdStrike’s software operates at the kernel level in Windows, meaning its process is operating with the highest level of privileges and access in the OS. This means it can crash the whole system; for example, by corrupting part of the OS’s memory. CrowdStrike operating at this level is necessary for it to oversee processes running across the OS, and to discover threats and vulnerabilities. But this also means that an update – even an innocent-looking content file! – can cause a crash. 5. Did the company ignore a previous similar outage? A Hacker News commenter working at a civic tech lab shared that, a few months ago, CrowdStrike caused a similar outage for their Linux systems. This dev summarized:
These details suggest that CrowdStrike could or should have been aware that it can – and does – crash kernel processes with updates. If so, the obvious question is why this outage did not serve as a warning to tweak the rollout process, as opposed to just improving testing? In fairness, a company like CrowdStrike has hundreds of engineering teams, and one team observing an outage is information that will not necessarily spread through the organization. Still, the CrowdStrike process crashing the OS was surely a known vulnerability, as it’s the most obvious way to brick a customer’s machine which it is meant to defend. Microsoft / Windows?Why can CrowdStrike run processes at kernel level which can crash an operating system? After all, Apple made changes to MacOS to run third-party software at user level, not kernel. From Electric Light, in 2021:
So on Mac, the same CrowdStrike process would run in the user space, and if it crashes it would not take the whole system down with it. However, on Windows and Linux, antivirus and other cybersecurity software usually runs at the kernel level, and always has done. So why hasn’t Microsoft followed Apple’s approach and banned third parties from the kernel space? Turns out that a Symantec complaint in the 2000s, and EU regulation, played a role. Regulation to blame?The Wall Street Journal asked Microsoft why it won’t limit third-party software like CrowdStrike to run only in the user space, not the kernel space. Its response:
Ironically, all of this started in 2006 with Microsoft wanting to make its kernel more secure for Windows Vista. From CIO.com at the time (emphasis mine):
In the end, Symantec and other vendors won. Microsoft could only “ban” security vendors from running in the kernel space if it also did not run its own security software there. So while Microsoft could be seen as partly responsible for this crash, the company had little choice in the actions which created the circumstances for it to happen! There would have likely been a way, though: if Microsoft moved their own security solution – such as Windows Defender – out of the kernel space, closing it off to all security vendors, including itself. Doing so would likely mean a large enough re-architecture of the Windows security stack. It would also limit the capabilities of third-party vendor solutions, and any such change would trigger outcry and more complaints to regulators by security vendors. It would be no different to the complaints and escalations of 2006, when Vista attempted to lock vendors out of the kernel space. 5. Learnings for software engineersHere are some learnings that us software engineers can take from this incident, as things stand: Quantify the impact of software crashing everywhereWhat happens if your company’s product crashes irrecoverably for a couple of hours? Ignore the fact that this seems so unlikely as to be impossible – because it has just happened to CrowdStrike. If it happened, what would the impact be on your company and the outside world? For example:
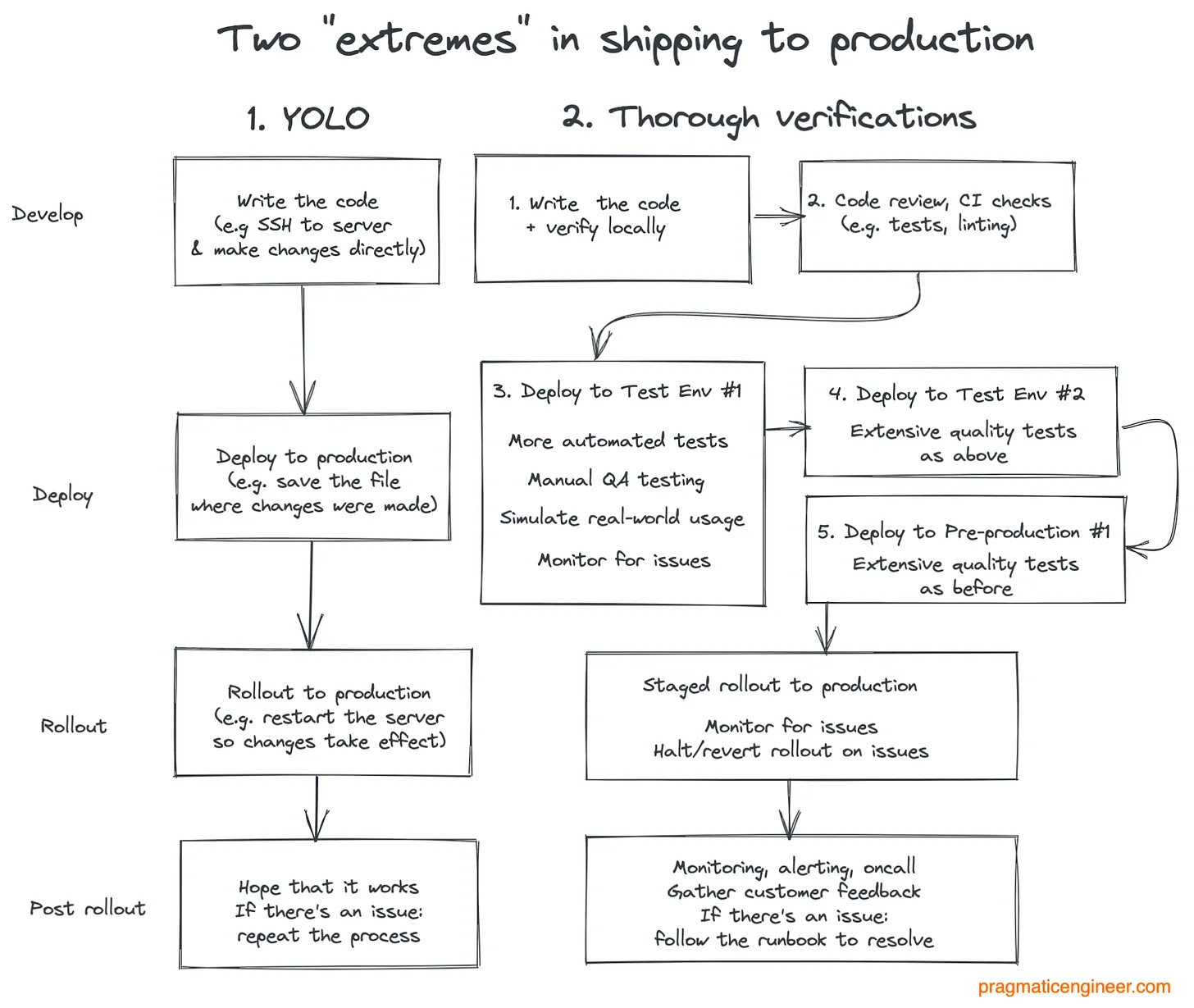
This exercise is helpful because it can give a sense of how expensive an outage could be. Knowing the “blast radius” can help get buy-in to make systems more resilient, and make it quicker to detect and mitigate incidents. Review how things reach productionWhat needs to happen for a code or asset change to be shipped to all customers? We go deep on this topic in Shipping to Production. As a recap, here are two extremes in shipping to production: CrowdStrike seems to have chosen the “YOLO” option for this change, and it cost them dearly:
Do canarying / staged rolloutsIf your software crashing everywhere has a big enough “blast radius” to make a failure unacceptable, then do not roll out changes to all customers at once! Do a canary or a staged rollout. It’s true that canarying and staged rollouts are overkill for certain products, like those with few users, or which do not generate revenue, or are experimental. Setting up canarying or staged rollouts is effort and does slow down rollout. But if your product is used by many people, or is critical enough, then this rollout strategy is non-negotiable. Take it from former Google Chrome engineer Marc-Antoine Ruel:
Treat configuration like codeStaff engineer Jacques Bernier formerly worked at Twitch and has shared how Amazon treated code changes:
What changes do dependencies/vendors “silently” push?CrowdStrike broke most customers’ businesses because it silently and automatically shipped business logic changes. Even if customers wanted to “block” a change, or only allow it for a subset of machines at first, they could not. It’s a good reminder that software can be broken not just by code, but by your dependencies or vendors. So now is a good time to consider these questions:
List all the points which could be affected by a faulty “silent” change from a third-party you use and (currently) trust. An outage is no one person’s faultIt’s easy to blame whoever wrote an offending piece of code for a crash; perhaps an intern lacking experience, or a veteran engineer having a bad day. But pointing the finger of blame at individuals is the wrong approach. Microsoft Veteran Scott Hanselman summarizes why a failure at this scale is never one person’s fault (emphasis mine:)
TakeawaysWidespread outages are always bad, but one upside is that they force us engineers to pause and reflect:
There’s no better time than now to make a case to your leadership for investing properly in reliability. The CrowdStrike outage is now officially the largest-ever software outage on the planet, and customers have suffered heavy financial and reputational damage. The financial loss is still unclear for CrowdStrike, but you can assume it will be huge, as some businesses will seek compensation for the damage done. For CrowdStrike, the reputational damage could hardly be worse. Until a few days ago, the company was the gold standard in endpoint security compliance. No longer: its name is linked with the biggest outage anybody’s seen. After such a high-profile blunder that reveals the company had no staged rollout processes in place for business rule changes (“channel files,”) the reputation of Crowdstrike has suffered a hit which it will take a long time to recover from. No business wants such a blow from a single bad deploy, but it’s happened. If you see gaps in your company’s release processes – testing, rollout, monitoring, alerting, etc – then now is the time to take your concerns and suggestions to the table! Talk with your manager or skip-level; they will be more likely to champion ideas which make production systems resilient. CrowdStrike is certain to learn its lesson, and doubtless its future release processes will be world class. Good luck to the team there (and teams at all affected customers) for mitigating the outage, and for work ahead at CrowdStrike to overhaul internal processes. Let’s hope many companies follow suit, so this historic event ends up being a net positive learning experience for the tech industry. We’ve previously covered outages with interesting learnings. Check out these for more analysis and learnings, and for making systems more reliable: You’re on the free list for The Pragmatic Engineer. For the full experience, become a paying subscriber. Many readers expense this newsletter within their company’s training/learning/development budget. This post is public, so feel free to share and forward it. If you enjoyed this post, you might enjoy my book, The Software Engineer's Guidebook. Here is what Tanya Reilly, senior principal engineer and author of The Staff Engineer's Path said about it:
|
The biggest-ever global outage: lessons for software engineers







Subscribe to:
Post Comments (Atom)
Top 3 UX Design Articles of 2024 to Remember
Based on most subscriptions ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ...
No comments:
Post a Comment