👋 Hey, Lenny here! Welcome to this month’s ✨ free edition ✨ of Lenny’s Newsletter. Each week I tackle reader questions about building product, driving growth, and accelerating your career. If you’re not a subscriber, here’s what you missed this month: Subscribe to get access to these posts, and every post. For more: Best of Lenny’s Newsletter | Hire your next product leader | Podcast | Lennybot | Swag In my quest to develop a comprehensive benchmark to measure progress toward AI replacing PMs, I teamed up with full-time prompt engineer (and past collaborator) Mike Taylor on a piece that will surely blow your mind. I’d love to hear your reactions in the comments.
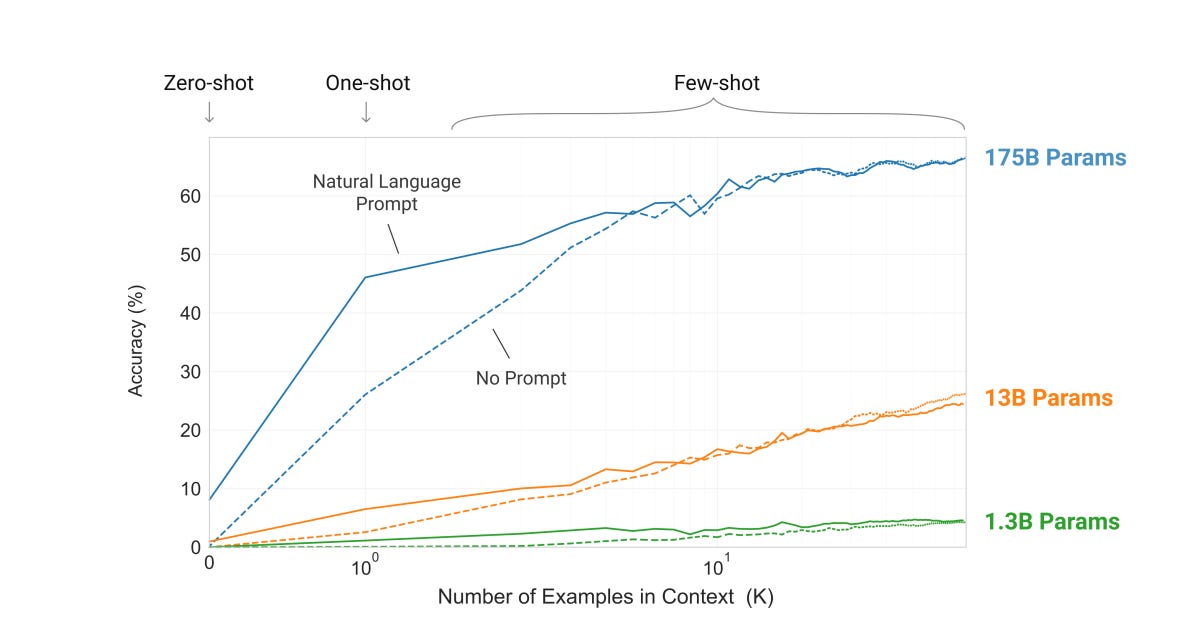
The AI industry moves fast, which leads to lots of confusion about what AI is actually good at. OpenAI, Anthropic, and all the other AI companies are constantly testing their latest models’ math, language, and coding abilities. However, these abstract benchmarks don’t tell us how much of your job AI is able to potentially replace, now or in the near future—which is really what we care about. To make matters more challenging, expert prompting is necessary to make responses from a model any good. As a result, most people underestimate how close ChatGPT and other tools are to replacing the work of a human. Whenever you see the headline of an article or scientific paper that says “ChatGPT can’t do x,” it’s usually because they didn’t use the latest model and didn’t make use of prompt engineering. For example, the authors of the paper “ChatGPT is fun, but it is not funny” used only basic prompts like “Tell me a joke, please!” and were testing GPT-3, not GPT-4. When I tried this same task myself, applying some prompting principles, I found that you can very much get the newer models of ChatGPT to tell a funny joke. “Language Models are Few-Shot Learners” showed that prompting techniques could drive around a 30% improvement in accuracy on some tasks, and if you add multiple examples of the task being done correctly, you can get an overall 50% to 60% accuracy boost.
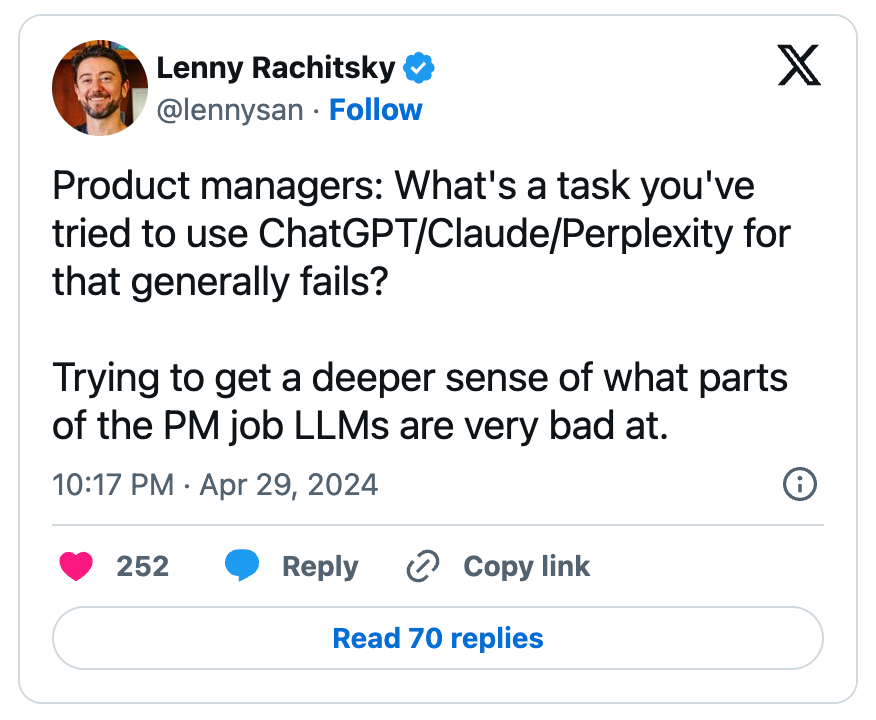
Thus, to realistically measure how close AI models are to replacing the work of a human—in our case, a product manager—we need to collect real-world examples of difficult PM tasks that AI tools seem to struggle with, use the best current model, and apply prompt engineering principles to give the models the best chance possible. (This is the same approach Google recently used to test Gemini 1.5’s capabilities.) I work as a professional prompt engineer and recently published a book with O’Reilly, Prompt Engineering for Generative AI, so I’ll use my prompting skills to see if I can get an AI tool to beat humans at a set of PM tasks. We’ll evaluate who “wins” at each task with blind Twitter/X polls, where voters don’t know which response is AI or human. From this exercise, our goal is to understand how close AI is to automating the PM role, and what task areas are most likely to be delegated first. Sourcing hard tasksTo establish a baseline of what tasks are hard for AI, Lenny put out a call for tasks that PMs have tried and failed at getting ChatGPT to do:
Our plan was to take three of these tasks and see if I could prompt the AI to do a better job than a human. Whether one answer to a task is “better” than another is subjective, even among humans. With AI in the mix, some people dislike its overly formal tone, verbosity, or lack of personality, while others appreciate AI’s comprehensiveness, objectivity, and well-structured formatting. For the purposes of this experiment, we're interested in both how people rate the answers and their comments about why. In order to run a fair test, we got people to rate which answer to the task was better, without revealing which was AI. The results were shocking:
This was only a small test, and AI is still a long way from working independently as a product manager. But it’s important to remember that right now is the worst AI will ever be at any task—these models may continue to get twice as good every six months. Our method for testing AI performanceFrom the initial shortlist of hard PM tasks we got in response to Lenny’s social posts, we selected three that we thought would be most impactful to day-to-day work:
My method was to look at what a typical human response to each task might be and then write a prompt to solicit a similar response quality and structure from AI. We then asked people on X which of the two answers they thought was better. Prompts were run in the OpenAI Playground (which is available to anyone with a developer account). This let us set our own system prompt (the instructions for how the model should behave) rather than using the ChatGPT system prompt, which has a lot of extra words that might throw off our test.
The actual evaluation poll was run by Lenny tweeting screenshots of two solutions, without saying which one was AI. People were encouraged to vote on which they thought was the better answer, and also tell us which one they thought was made by AI:
We ran this as a blind test because that’s the only fair way to evaluate performance. Think of it like the Coke vs. Pepsi challenge: when Pepsi is in unmarked containers, people prefer the taste, but when people see the Coca-Cola brand on the can, they prefer that instead. Given that people have so many opinions on AI, both positive and negative, revealing which response was AI could have skewed the test. (Perhaps it’s self-preservation, but when I compare AI output with my own work, I think it’s bad, yet when I run blind tests, people often prefer the AI.) Finding training and evaluation dataThe hardest part of doing a blind evaluation was finding real examples and results from a human doing the task. When we googled these PM tasks, we mostly got blog posts with advice on how to approach the task, but with no tangible real-world examples. One rare exception was the fantastic PM interview questions database curated by Exponent (no affiliation; I just like their content), a website that helps people prepare for job interviews at top-tier tech companies like Google, DoorDash, Amazon, Airbnb, Spotify, and Meta and is the official interview prep partner for schools like Stanford, Yale, Cornell, and Columbia. We used PM answers from Exponent as the human responses for all three selected tasks. I’ll add that there could certainly be better human answers, but thousands of PMs are using these answers in their interview prep monthly, so it’s a strong benchmark to use. Test resultsNow let’s get to the test results. We’ll first present the task and the two solutions (one AI, one human). Then we’ll reveal how they did when we tested them with X polls and discuss what that means for product managers today. After sharing the results, I’ll also share my prompts for you to use and explain what techniques I deployed to get above-average results. Task #1: Developing a product strategyWhat AI struggles with:One of the most common complaints about AI is that it can’t think creatively, and therefore makes for a poor sparring partner when developing a strategy. This is so pervasive that I’ve even seen people claim they use ChatGPT to decide what not to do, to avoid any strategy or action that was too obvious.
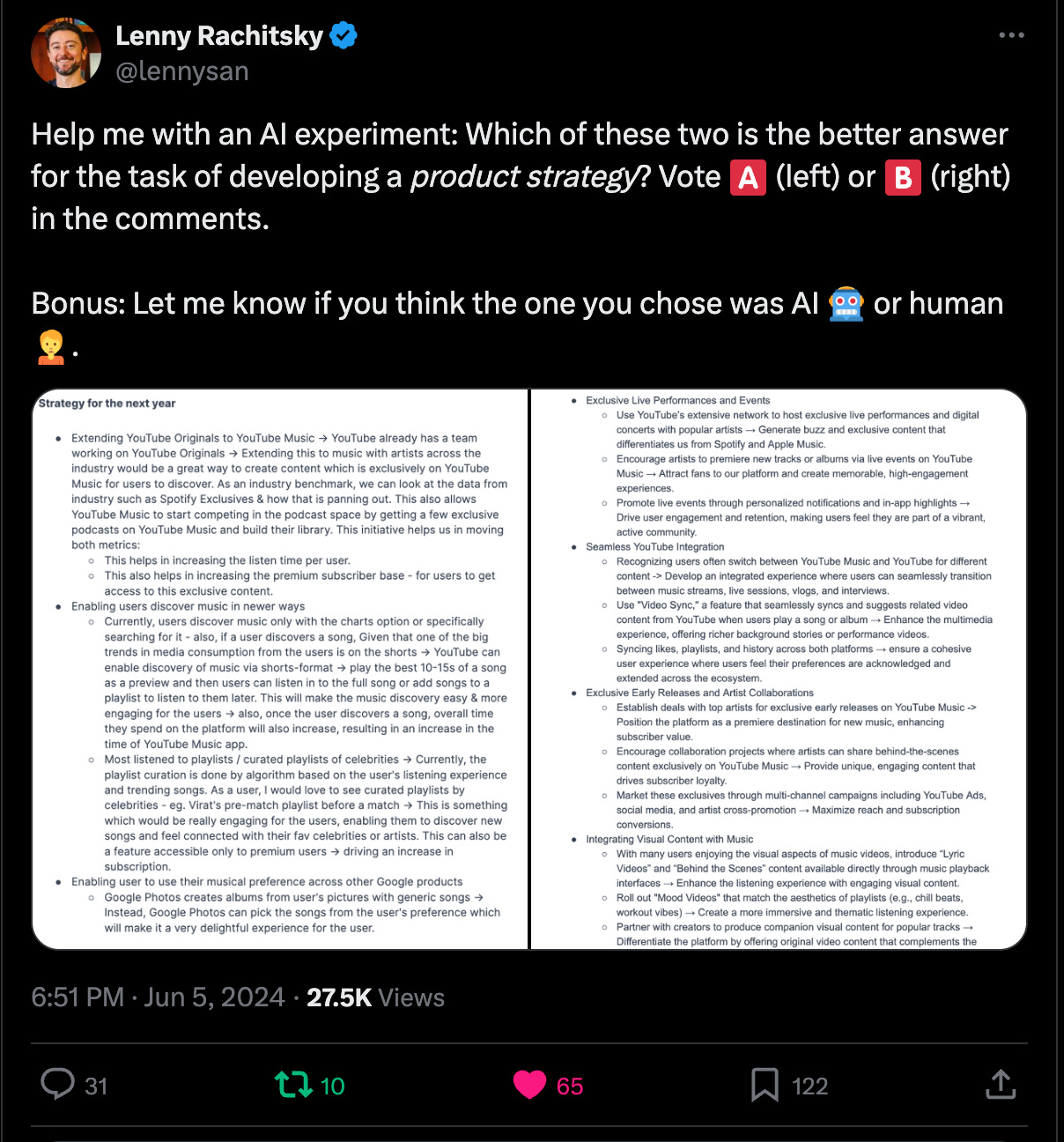
This is a clever use of AI, but I feel that it sells the technology’s capabilities short. LLMs are trained on all the text available on the internet (and beyond), so the default answer you get is going to be approximately the average of the internet. But with better prompting, you can do much better than average, by steering it toward less obvious answers. Developing a strategy is the skill Lenny thinks will become most dominated by AI, so let’s see where it’s at today. The real-world scenario we tested:Imagine you’re the PM for YouTube Music. What is your strategy for the next year? Solution A:
Solution B:
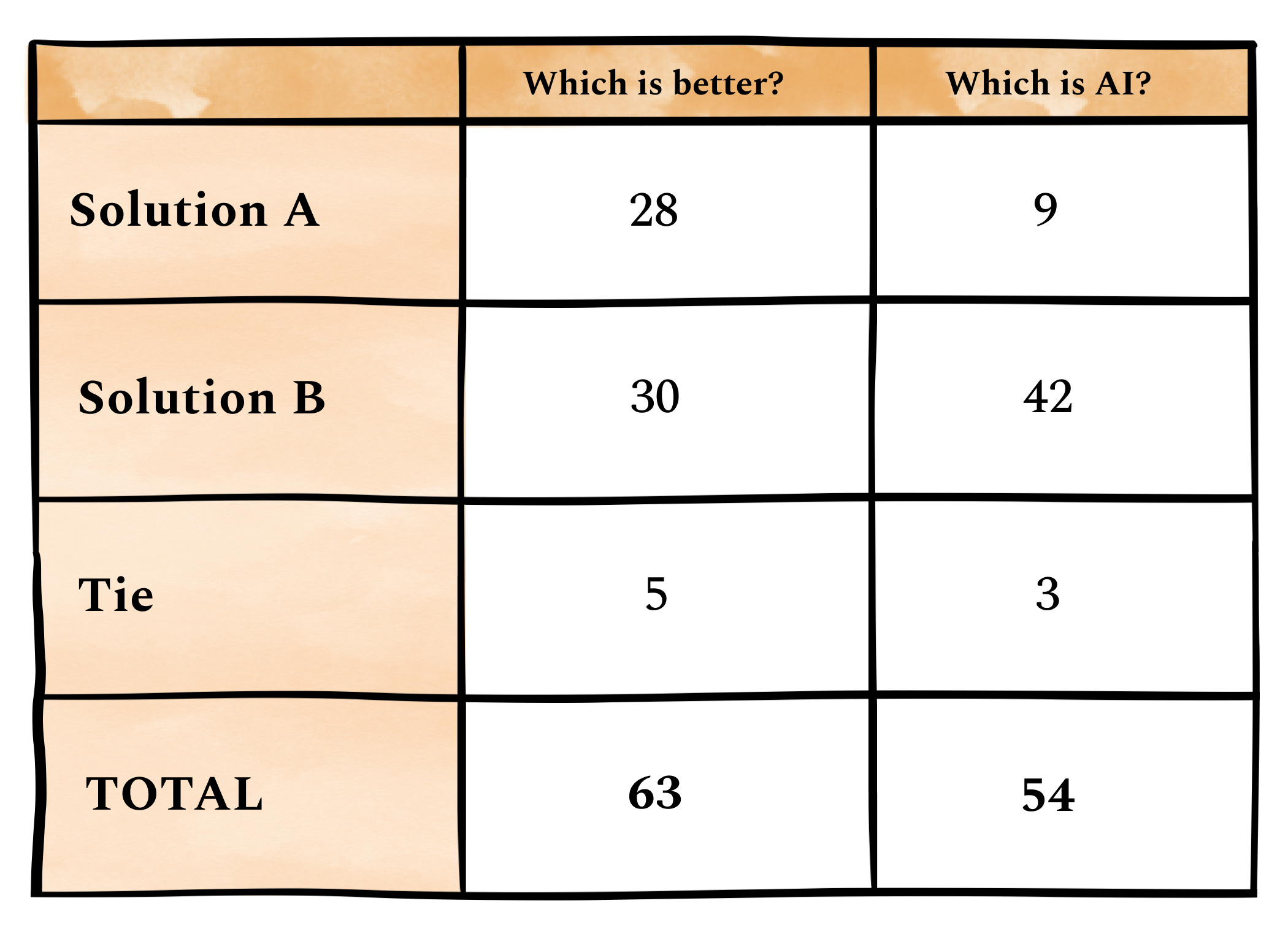
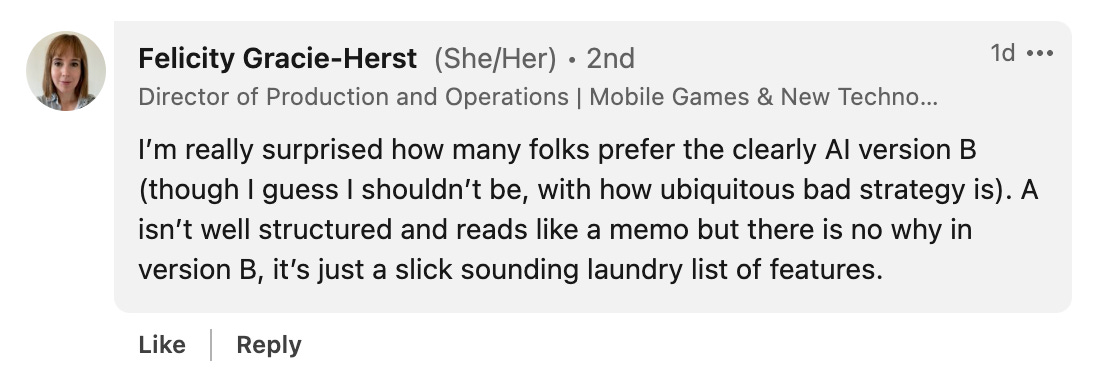
Which was the winner?The preferred solution was B, which was the AI version, with 55% of the votes (when you include tied votes)! This was a close contest, but a tie is still a win for AI, because it’s so much cheaper and quicker to have AI develop your strategy versus a human. Shockingly, solution B won despite 77% of people correctly guessing it was the AI answer. The human answer comes from Harshit G’s answer to a job interview question on Exponent. Given that product strategy is so, well … strategic, I’d suspected AI would be further behind on this task. The overriding criticism of the AI version, B, was that it felt like a list of features, rather than a true strategy. I expect this is fixable over time: reasoning ability is an active research area and will likely be the next major leap forward with GPT-5. Humans win on actually being strategic (versus tactical), for now.
I put a lot of work into the prompts to make it harder to guess which was AI, because I assumed people would reject the AI work if they knew it wasn’t human. Not so, as the majority of people who voted for B knew it was AI but still chose it as the better answer. This was unprecedented for me, and it says a lot about the growing familiarity with and acceptance of AI tools.
Sometimes it’s small details that humanize our work, as in solution A, which mentions a famous cricket player. AI by default produces average answers based on the highest-probability answer, whereas humans can surprise and delight with unexpected connections between concepts. To make your work more noticeably human and less replaceable by AI, incorporating your niche interests and passions into your work seems like it would be a good strategy.
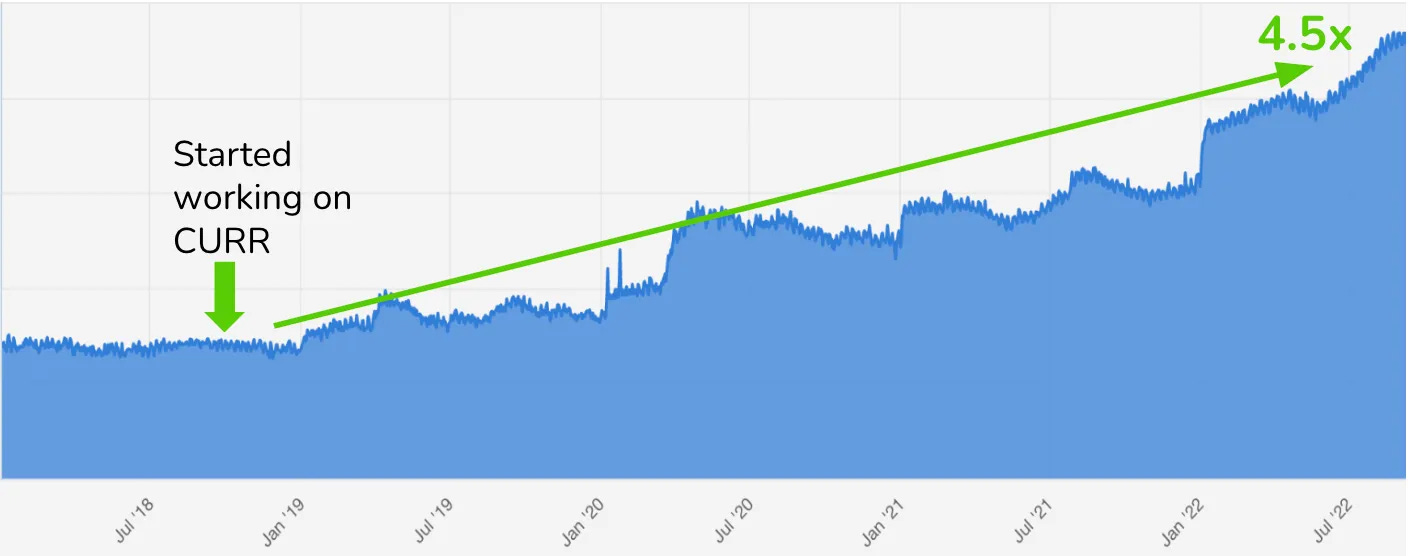
One thing to note is that we changed up the prompt slightly between X and what we posted on LinkedIn. There were a couple of dead giveaways in the first version of solution B posted on X that I wanted to see if I could correct for by adjusting the prompt. For example, the human solution, A, had grammatical errors and a niche reference to a famous cricketer, so I added instructions to my prompt to “add obscure references” and “make some minor grammatical mistakes due to being busy.” As a result, the score did differ between the social networks, giving AI an advantage on LinkedIn: 59% versus 38%. If we had run v2 of solution B on both social platforms, AI would have had an even more dominant win. Task #2: Defining performance metricsWhat AI struggles with:Many of the comments we got on social media mentioned that ChatGPT had a lack of creativity in coming up with performance metrics, and, to be fair, this is a tricky topic that most humans also get wrong. I worked for over 200 startups as a growth-marketing-agency owner, and I would say that less than 10% were confident they were measuring the right performance metrics. But when you do, you can unite an entire organization around a single goal, and magic happens—as was the case with Duolingo and CURR (current users retention rate), a key metric they focused on.
While ChatGPT does perhaps tend to go with the obvious metrics (I haven’t seen it come up with anything as creative as CURR), I was confident we could get it thinking a little deeper about how different metrics stack together. The key was breaking things down by department before bringing everything together in a North Star goal, which is an approach I saw often in human-written responses to this type of task. The real-world scenario we tested:What are the most important metrics for DoorDash? Solution A:
Solution B:
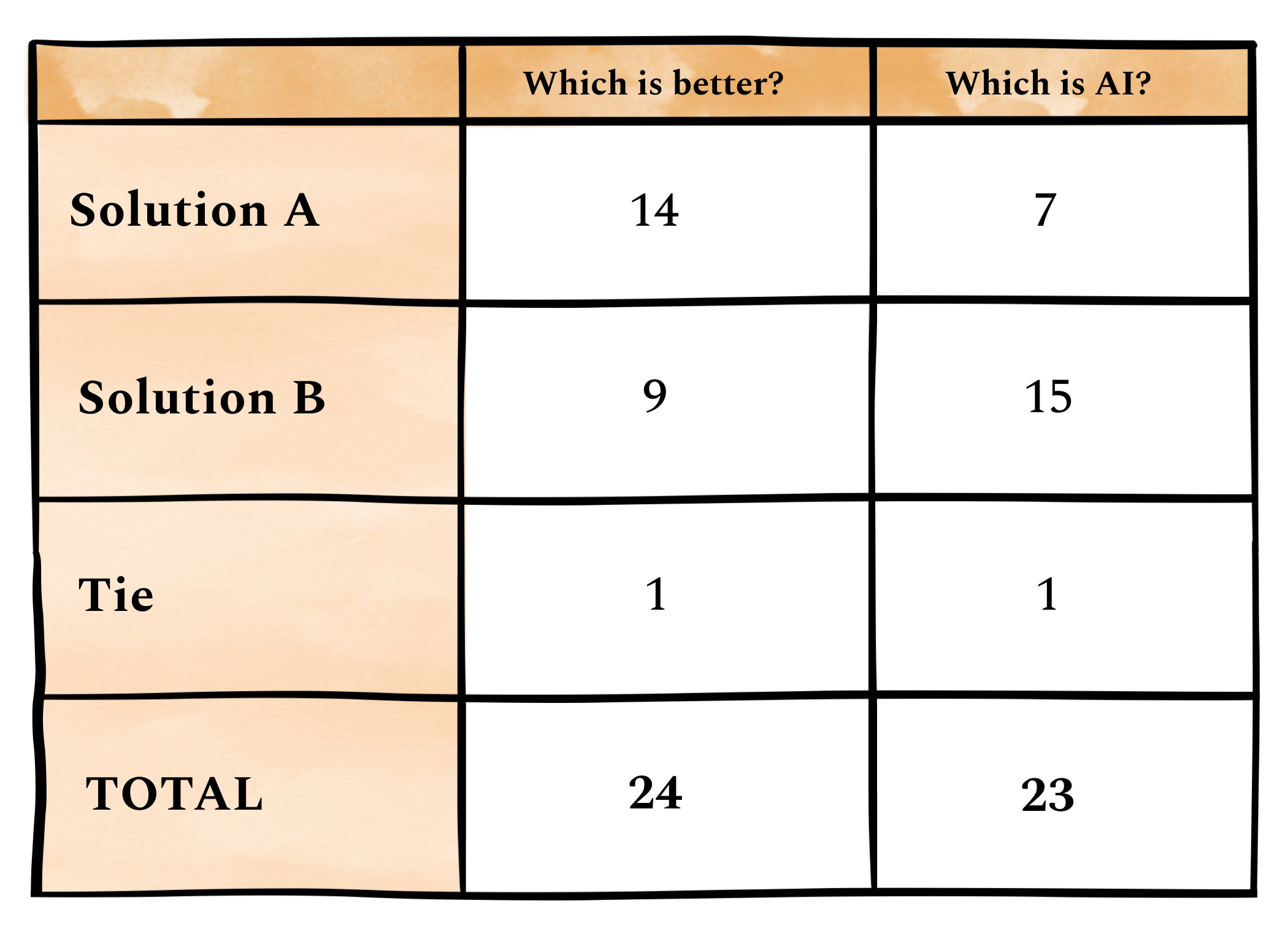
Which was the winner?The preferred solution was A, with 68% of the votes. This was the AI version, which 70% of people guessed correctly. If you credit any tied votes to AI, it scored 86%! The human answer comes from Anonymous Muskox’s answer to a job interview question on Exponent.
This was a big win for the AI, with a majority of people admitting it was the better answer despite suspecting it was done by the AI. Again the primary way of identifying AI was that it gave a more comprehensive answer. I actually took steps to decrease the verbosity considerably with this prompt, but it was still enough to get noticed. However, for short tasks like this I have found that being more verbose than a human can sometimes lead to a better answer overall. Many people were fairly certain that A was AI, and they cited how comprehensive or long-winded the answer was as the obvious tell. If you’re trying to hide whether your answer was AI-generated, finding ways to get it to quit yapping seems to be the key.
Sometimes people were wrong about whether an answer was AI but were right in their criticisms. I think if we can get AI to be considered on the same level as a human, that in itself is a win, because AI costs pennies and takes seconds to answer, so can be scaled significantly, leaving human product managers to do higher-value work, or do the research necessary to get us past intern level.
We saw many ties across the tests we ran, sometimes because respondents thought both were equally good and other times because they were equally bad. Whether equally good or bad, equal is a win for AI! Especially when you consider it will continue to get better from here, with every possibility that in 6 to 12 months AI could be edging out the average human across multiple PM tasks. We do have to remember that this is a very hard test for AI, given that Lenny’s audience is full of experienced product managers who likely have their own opinions on how to do the task.
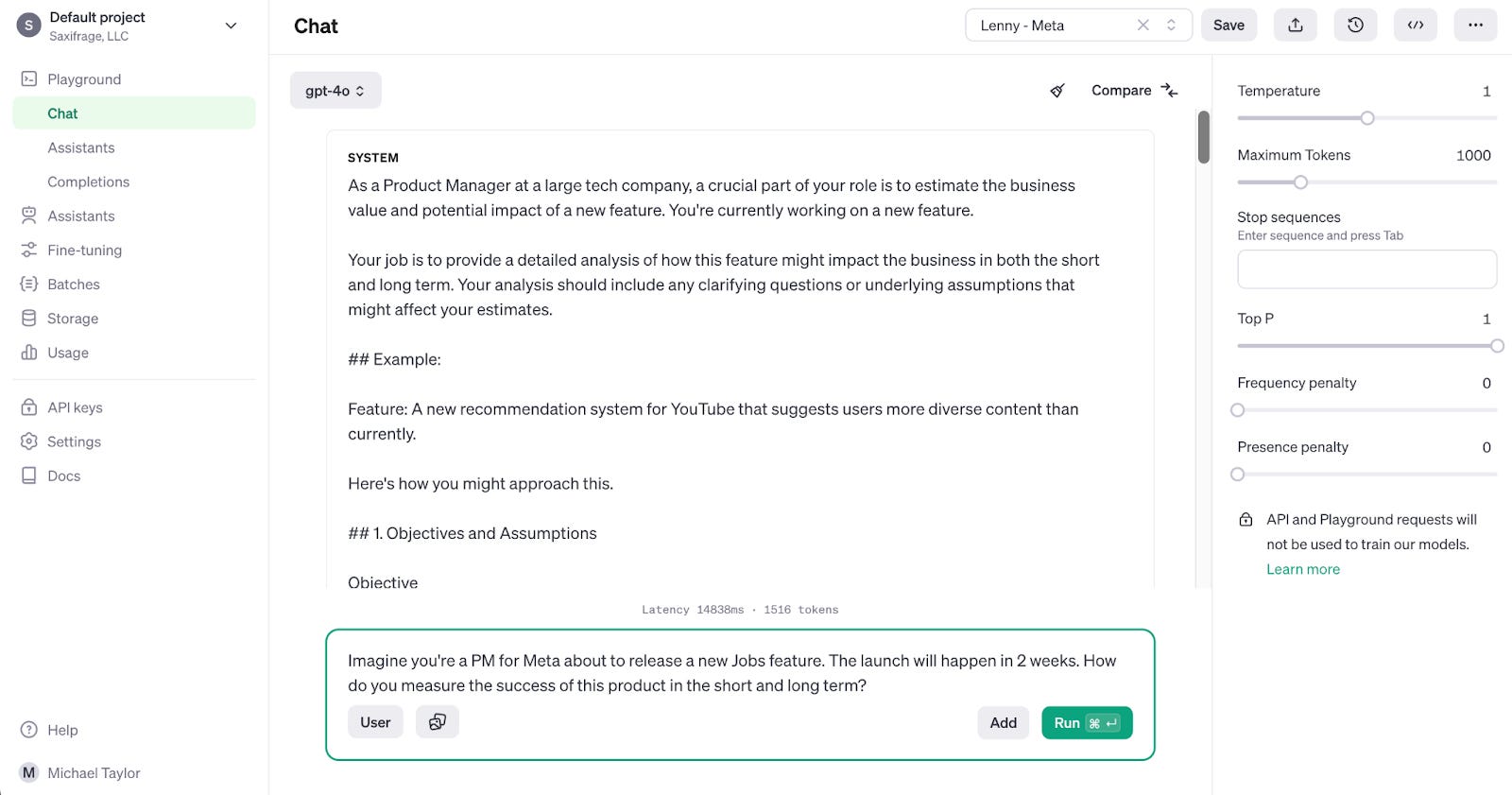
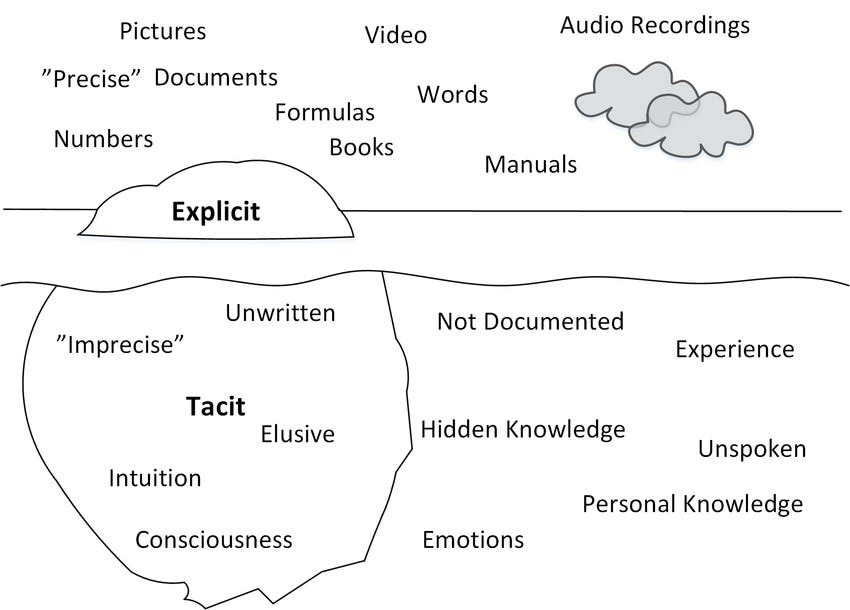
Task #3: Estimate ROIWhat AI struggles with:Another task many PMs were frustrated with getting AI to do well was prioritizing product features. The difficulty with this type of task is that ChatGPT doesn’t have all of the context that you have about your organization and the various tradeoffs that need to be made. AI chatbots that “talk to your data” still don’t solve the problem that most of the important things in your organization are tacit, not explicit, knowledge, and not written down anywhere. In the future, when AI tools have been a fly-on-the-wall participant in every conversation across your business, can access all of your documents, and can fit all of that in its context window (the amount of information it can take into the prompt), they will likely become superhuman at estimating ROI in particular. However, even without these advantages, I’d suspected that AI could be better with just a little bit of advanced prompting. The real-world scenario we tested:Imagine you’re a PM for Meta about to release a new Jobs feature. The launch will happen in 2 weeks. How do you measure the success of this product in the short and long term? Solution A:
Solution B:
Which was the winner?The preferred solution was A, with 58% of the votes, which was the human version. This was a very close race, with many people saying they only picked A for marginal reasons. And only 65% of people guessed correctly which was AI. The human answer comes from Avi G’s answer to a job interview question on Exponent. I actually modified it by adding the numbers, as the original human answer didn’t supply any estimates and I wanted it to be a fair fight. I suspect the AI would have won if it was the only one with numbers. We got far fewer people voting on this one; I guess I scared people away with the math! So we posted it on LinkedIn as well to get more votes. This time we kept both versions the same as what we tested on X. One of the common misconceptions is that LLMs are bad at math (an early weakness of LLMs that is now largely solved with chain-of-thought prompting), so I think I would have fooled more people with this. If you give LLMs plenty of thinking time so they can work things out step-by-step, they are actually fairly good at providing reasonable estimates. Nevertheless, we got a very tight race for the AI and saw a lot of the same patterns we saw in other tests. When I’m evaluating AI performance for my clients, it frequently becomes clear that we aren’t putting enough effort into measuring human performance. There were disagreements on whether the human answer was good or not, as it did not focus on monetization metrics. Given that this theoretical task was for Meta, which is famously willing to forgo profits for decades before switching on monetization for a feature/platform, I think it’s fair to say that the human-given answer “$ made” wouldn’t be the main metric for launching a new feature. Plenty of PMs disagree, however, and that’s particularly valid now that the era of zero-percent interest rates is over and VC funding is less frothy. How you measure impact is a function of how you measure strategy, which is why these tasks are always going to be somewhat subjective.
In their comments on X and LinkedIn, many people guessed which option other people would vote for, separate from their own rating. This adds another interesting dimension to evaluations where the responses are public: there’s a risk of groupthink once the vote sways in one direction, and bias if our mental models of what other people think about AI are out of date. I’m finding that attitudes to AI are changing rapidly over time, and clients that were previously skeptical of AI are suddenly all-in months later. It’s best to run private blind tests periodically to see what people really think about AI results.
Another type of answer I saw a lot was “neither was good.” This may be a function of conducting the test publicly in Lenny’s social media feed, where many ambitious PMs are hoping to prove themselves and stir up a discussion. The next time I do this test, I would give people a way to vote privately, and I suspect that would lead to more interesting results—and perhaps even more favorability toward AI results.
What comes next?Testing head-to-head on three tasks isn’t a comprehensive evaluation, so we want to extend these benchmarks across more types of difficult PM tasks. This section describes our suggested approach to doing so. We’d love to hear from you in the comments here on Substack or on social media about which may be good ideas, and what we may have missed that would make the results more trustworthy and believable to you. Lenny once defined the job of a product manager as to “deliver business impact by marshaling the resources of your team to identify and solve the most impactful customer problems.” He also defined a comprehensive framework for categorizing PM skills (below). Aligning the hard PM task benchmarks with this framework will help us track what percentage of the overall PM role is currently automatable.
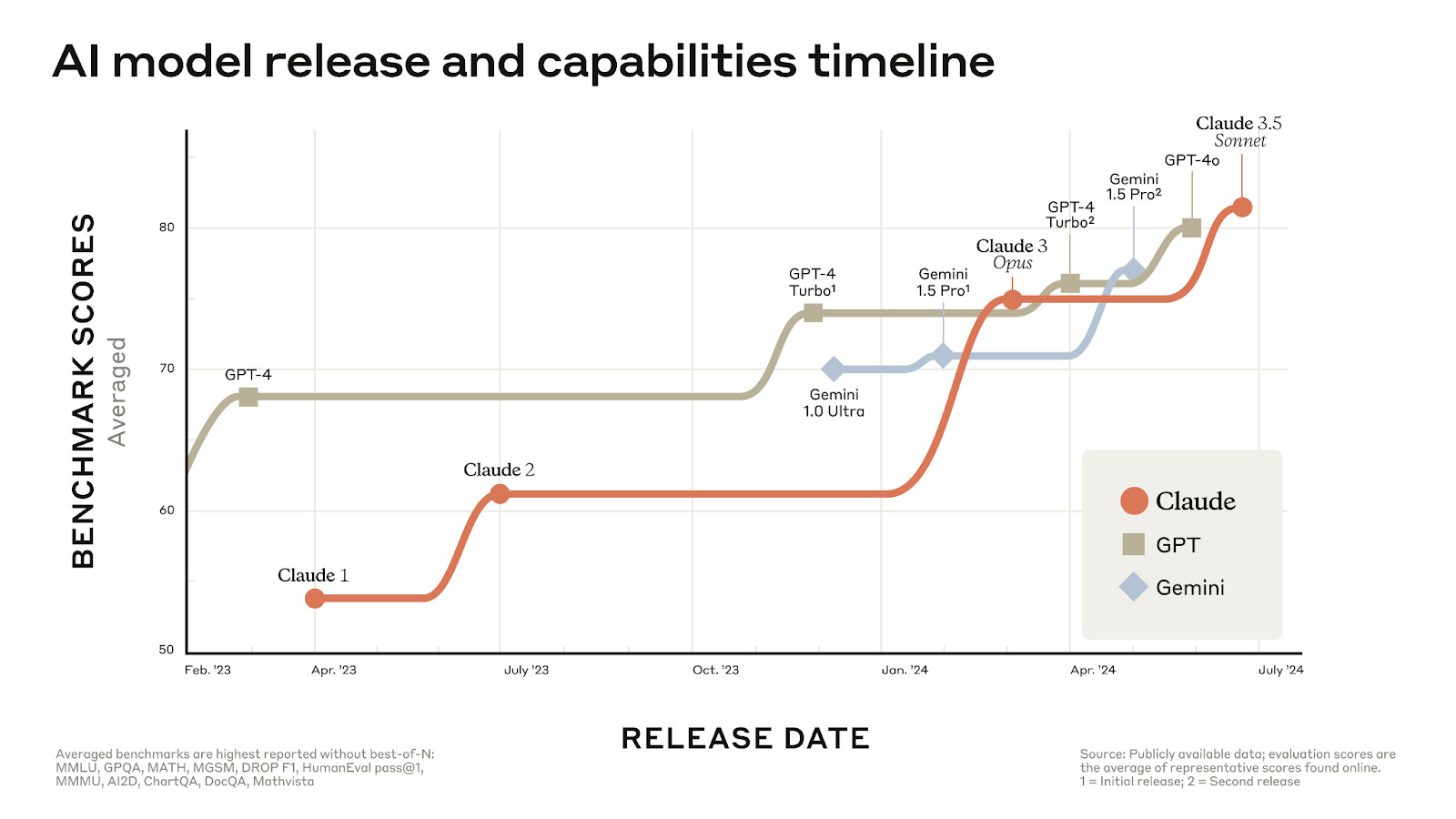
To go even deeper, we would explore multiple questions per category to get more diverse and robust results, and run the tests with more models (and potentially different prompting techniques). In particular, I would love to explore whether Claude 3.5 or Google Gemini 1.5 can beat GPT-4o, and how giving a model access to the internet, like Perplexity has, may change which tasks it can compete at. One big problem is data contamination, where the LLMs learn which answers are “correct” when they are trained on fresh data from the internet, which includes posts like this one that document common LLM failures and reveal what the correct answers are. With an updated post, we would avoid data contamination of the evaluation benchmark by not revealing which solution was AI and just tallying the aggregated results. This would make the evaluation benchmark less accessible (people wouldn’t be able to run the evaluation themselves if we don’t reveal the correct answers), but hopefully there are researchers out there with good suggestions on this front. The voting mechanism we used wasn’t ideal. Posting on X and LinkedIn and then tallying the votes manually was too open to interpretation, and took too long to be able to run tests more frequently. We would need to change the methodology to support an expanded list of tasks. For inspiration, we’re thinking about how LMSYS handles their chatbot arena, but we’re open to suggestions. The major difference is that we’d also need to collect real human answers to questions like Exponent does and compare them against the LLM responses.
Bonus: How I created the prompts for these tasksThere are plenty of prompt engineering techniques and tactics to employ to get better performance from AI, but for this exercise I wanted to develop something more formulaic. Here is the process I settled on:
The prompt template structure ends up as follows:
Role Many of these tasks are a kind of cultural and political game, where the type of answer that would seem “obvious” to a Silicon Valley executive might feel completely alien to the boss of a consumer packaged goods company. The important part of this prompt is asking the AI to role-play as “As a product manager for a major tech company…,” which helps it get the right cultural references and acronyms that a product manager would use. Without role-playing, you get an average response, which might not match your subjective tastes. Instructions One of the mechanisms that makes this prompt work is the instruction to “Start by listing assumptions...” AI models (and humans) tend to give better answers when they spend some time planning the answer first, which OpenAI calls “Giving the model time to think,” also called “chain of thought” prompting. In the example I added to the prompt, I made sure to add that assumptions and clarifying questions section so that the model could follow my lead and arrive at a more robust answer. There were also smaller optimizations to the instructions for specific tasks, like in task #1 where I specifically asked it to make obscure references and make minor grammatical mistakes. Example The most impactful thing in the prompt template is the example we provided. It’s hard to describe exactly how a task should be done, and providing an example allows the AI to pick up on nuances we might not be sufficiently able to describe. Adding at least one example massively improved the reliability of the results, and adding additional examples from a diverse range of scenarios helped further. Although too many examples ran the risk of constraining the AI’s output creativity, as it might follow the examples too strictly. In addition, collecting good examples comes with a cost of your time, so I would try to add a single example first to see if that does a good enough job. Here are the final prompts I used: Task #1:
Task #2:
Task #3:
FootnotesSome further details on the tests we ran:
This isn’t intended as a scientific test, but the results should make you think about whether you have been judging AI unfairly, and perhaps it’s further along than you may realize! Thanks, Mike! Mike Taylor co-authored the O’Reilly book Prompt Engineering for Generative AI and builds AI products at Brightpool. Previously, he built a 50-person marketing agency, working with clients like Booking.com, Time Out, and Monzo. Follow him on LinkedIn and X. Have a fulfilling and productive week 🙏 👀 Hiring? Or looking for a new job?I’m piloting a white-glove recruiting service for product roles, working with a few select companies at a time. If you’re hiring for senior product roles, apply below. If you’re exploring new opportunities yourself, use the same button above to sign up. We’ll send over personalized opportunities from hand-selected companies if we think there’s a fit. Nobody gets your info until you allow them to, and you can leave anytime. If you’re finding this newsletter valuable, share it with a friend, and consider subscribing if you haven’t already. There are group discounts, gift options, and referral bonuses available. Sincerely, Lenny 👋
Invite your friends and earn rewardsIf you enjoy Lenny's Newsletter, share it with your friends and earn rewards when they subscribe.
|
How close is AI to replacing product managers?













Subscribe to:
Post Comments (Atom)
Top 3 UX Design Articles of 2024 to Remember
Based on most subscriptions ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ...
No comments:
Post a Comment